This is the breakdown of how I built Find a Sub, a Recommendation Engine for Reddit.
It might be helpful while you read the blog post if you clone the repository with the code.
The reason why I built this is because I think that the default ways to discover Subreddits is not optimal. Basically there are two ways (that I can think of) to find new subreddits.
Going to subreddits such as Bestof of Subreddit of the day to find new subreddits.
For each subreddit I like, check the sidebar for recommended subreddits.
The problem with any of those approaches is that they don’t consider myself as a Redditor who likes multiple subreddits to provide me with relevant subreddits.
So I thought, why not building my own recommendation engine for Reddit?
Here i will explain in depth, how i did it.
Step 1. Lay out the problem
When doing any kind of project, it always helps to write down the project and break it down in smaller tasks that are easier to acomplish.
In this case, what we are looking to build is a tool that:
given a Reddit user,
will get that user’s information and
use that information to provide back to the user new subreddits that he/she is likely to like.
Which makes sense, but let’s go deeper.
Step 1b. Layout the problem (more in detail)
Ok, so now that we know we need to recommend new subreddits based on a set of user information, how do we do it?
The most obvious and easy way to implement this is to use a set of subreddits that a user has commented to and use that set of subreddits to find new ones.
Another option would be to use all the subreddits a user is subscribed to instead of those subs where he/she has commented on, isn’t it.
However, because of how Reddit works, its fairly easy to find out which comments a user has posted, but impossible to find out all the subreddits a user is subscribed to.
Here we are introducing our first bias on the recommendation engine. By using a user comments as a source for the similarity we are giving more weight to those subreddits where users comment more.
This doesn’t mean that the recommendation engine won’t work, just that those subreddits where there are more proportion of leechers (people who don’t contribute, just consume the contents) will be less likely to be recommended.
So for a specific Reddit user, we will find the subreddits that user has commented on, and we will recommend new subreddits to him/her.
How will we know which subreddits are similar to each other?
Well, let’s talk a bit about…
Defining similarity
 I’m sure you know what similarity means, don’t you?
I’m sure you know what similarity means, don’t you?
However, there are multiple ways of defining similarity, or say diferently, there are many similarity measures and each way applies to specific kinds of entities.
For example, a way to define how similar two words are is by using the edit-distance similarity, which takes into account how many changes would need to be applied to a word to become another. That measure would be hard to apply to two pictures of cats for example.
In this scenario we want to calculate how similar subreddits are. That means we will need to compute the similarity between each pair of subreddits.
So our main task is to create a table that looks like
sub1 | sub2 | similarity
funny | aww | similarity(funnny-aww)
funny | Iama | similarity(funny-Iama)
...
And so on.
Like I mentioned before, different similarity measures can be applied to different entities. In this case, we want to find similarities between subreddits.
And what are subreddits? Basically groups of redditors. So for this specific problem, among the many similarity coefficents available I chose Jaccard’s Index , which is defined as:
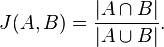
That little formula basically says that the similarity between group A and group B can be defined as the number of elements that belong to group A and B divided by the number of elements that belong to the group A or B.
Great! so now we know, that in order to calculate the similarity between subreddits, we just need to get a list of all the redditors on each sub.
Which leads us to part 2 of this tutorial, or how to build the dataset.